Haykin cu rețele neuronale curs complet pdf. Greșeli de tipar în cartea lui Simon Haykin „Rețele neuronale: cursul complet”

În am descris cel mai mult proprietăți simple neuroni formali. Am vorbit despre faptul că sumatorul de prag reproduce mai exact natura unui singur vârf, iar sumatorul liniar vă permite să simulați răspunsul unui neuron, constând dintr-o serie de impulsuri. Ei au arătat că valoarea la ieșirea unui sumator liniar poate fi comparată cu frecvența vârfurilor evocate ale unui neuron real. Ne vom uita acum la proprietățile de bază pe care le au astfel de neuroni formali.
filtru Hebb
În cele ce urmează, ne vom referi adesea la modele de rețele neuronale. În principiu, aproape toate conceptele de bază din teoria rețelelor neuronale au relatie directa la structura creierului real. Omul, confruntat cu anumite probleme, a venit cu multe modele interesante de rețele neuronale. Evoluția, trecând prin toate mecanismele neuronale posibile, a selectat tot ceea ce s-a dovedit a fi util pentru ea. Nu ar trebui să fie surprinzător că pentru multe modele inventate de om pot fi găsite prototipuri biologice clare. Întrucât narațiunea noastră nu își propune să prezinte în detaliu teoria rețelelor neuronale, vom atinge doar punctele cele mai generale necesare pentru a descrie ideile principale. Pentru o înțelegere mai profundă, vă recomand cu căldură să apelați la literatura de specialitate. Cât despre mine cel mai bun manual pe rețelele neuronale - acesta este Simon Haykin „Rețele neuronale. Curs complet” (Khaikin, 2006).Multe modele de rețele neuronale se bazează pe binecunoscuta regulă de învățare Hebbian. A fost propus de fiziologul Donald Hebb în 1949 (Hebb, 1949). Într-o interpretare ușor liberă, are un sens foarte simplu: conexiunile dintre neuronii care se declanșează împreună ar trebui întărite, conexiunile dintre neuronii care se declanșează independent ar trebui să slăbească.
Starea de ieșire a sumatorului liniar poate fi scrisă:
Dacă inițiam valorile inițiale ale greutăților cu valori mici și furnizăm diverse imagini ca intrare, atunci nimic nu ne împiedică să încercăm să antrenăm acest neuron conform regulii lui Hebb:
Unde n– pas de timp discret, – parametrul ratei de învățare.
Cu această procedură creștem ponderile acelor intrări cărora li se aplică semnalul, dar facem asta cu cât este mai puternic. reacție mai activă neuronul de învățare însuși. Dacă nu există nicio reacție, atunci învățarea nu are loc.
Adevărat, astfel de greutăți vor crește fără limită, astfel încât normalizarea poate fi aplicată pentru a se stabiliza. De exemplu, împărțiți la lungimea vectorului obținut din „noile” greutăți sinaptice.
Cu o astfel de învățare, greutățile sunt redistribuite între sinapse. Este mai ușor să înțelegeți esența redistribuirii dacă monitorizați modificarea greutăților în doi pași. În primul rând, atunci când un neuron este activ, acele sinapse care primesc un semnal primesc un supliment. Greutățile sinapselor fără semnal rămân neschimbate. Normalizarea generală reduce apoi greutățile tuturor sinapselor. Dar, în același timp, sinapsele fără semnale pierd în comparație cu valoarea lor anterioară, iar sinapsele cu semnale redistribuie aceste pierderi între ele.
Regula Hebb nu este altceva decât o implementare a metodei de coborâre a gradientului de-a lungul suprafeței de eroare. În esență, forțăm neuronul să se adapteze la semnalele furnizate, de fiecare dată deplasându-și greutățile în direcția opusă erorii, adică în direcția anti-gradientului. Pentru ca coborârea în gradient să ne conducă la un extremum local fără a-l depăși, viteza de coborâre trebuie să fie destul de mică. Care în învățarea hebbiană este luată în considerare de micimea parametrului.
Miciunea parametrului ratei de învățare ne permite să rescriem formula anterioară ca o serie în:
Dacă renunțăm la termeni de ordinul doi și mai mari, obținem regula de învățare a lui Oja (Oja, 1982):
Aditivul pozitiv este responsabil pentru învățarea Hebbian, iar aditivul negativ este responsabil pentru stabilitatea generală. Înregistrarea în această formă vă permite să simțiți modul în care un astfel de antrenament poate fi implementat într-un mediu analog, fără a utiliza calcule, funcționând numai cu conexiuni pozitive și negative.
Deci, un astfel de antrenament extrem de simplu are proprietate uimitoare. Dacă reducem treptat rata de învățare, ponderile sinapselor neuronului antrenat vor converge la astfel de valori încât producția sa începe să corespundă primei componente principale, care ar fi obținută dacă am aplica procedurile adecvate de analiză a componentelor principale la datele furnizate. Acest design se numește filtru Hebb.
De exemplu, să transmitem o imagine pixelă la intrarea unui neuron, adică asociem un punct de imagine la fiecare sinapsă a neuronului. Vom furniza doar două imagini la intrarea neuronului - imagini cu linii verticale și orizontale care trec prin centru. Un singur pas de învățare - o imagine, o linie, orizontală sau verticală. Dacă aceste imagini sunt mediate, obțineți o cruce. Dar rezultatul învățării nu va fi similar cu media. Aceasta va fi una dintre rânduri. Cea care va apărea mai des în imaginile trimise. Neuronul nu va evidenția medierea sau intersecția, ci acele puncte care apar cel mai adesea împreună. Dacă imaginile sunt mai complexe, rezultatul poate să nu fie atât de clar. Dar aceasta va fi întotdeauna componenta principală.
Antrenarea unui neuron duce la faptul că o anumită imagine este evidențiată (filtrată) pe scalele sale. Când este dat un nou semnal, cu cât potrivirea dintre semnal și setările de greutate este mai precisă, cu atât răspunsul neuronului este mai mare. Un neuron antrenat poate fi numit neuron detector. În acest caz, imaginea care este descrisă de scalele sale este de obicei numită stimul caracteristic.
Componentele principale
Însăși ideea metodei componentelor principale este simplă și ingenioasă. Să presupunem că avem o succesiune de evenimente. Fiecare dintre ele le descriem prin influența sa asupra senzorilor cu care percepem lumea. Să presupunem că avem senzori care descriu caracteristicile. Toate evenimentele pentru noi sunt descrise de vectori de dimensiune. Fiecare componentă a unui astfel de vector indică valoarea celui de-al-lea atribut corespunzător. Împreună formează o variabilă aleatorie X . Putem descrie aceste evenimente ca puncte în spațiul -dimensional, unde axele vor fi semnele pe care le observăm.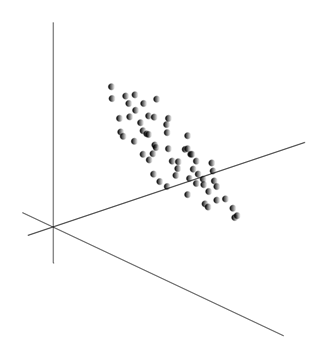
Media valorilor oferă așteptarea matematică a unei variabile aleatorii X, notat cu E( X). Dacă centrem datele astfel încât E( X)=0, atunci norul de puncte va fi concentrat în jurul originii.

Acest nor poate fi alungit în orice direcție. După ce am încercat toate direcțiile posibile, putem găsi una de-a lungul căreia dispersia datelor va fi maximă.
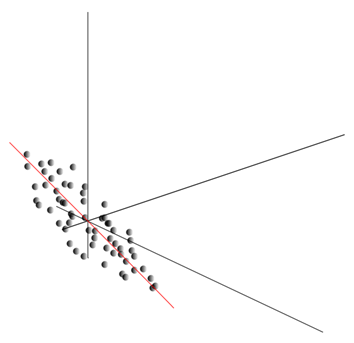
Deci, această direcție corespunde primei componente principale. Componenta principală în sine este determinată de un vector unitar care emană de la origine și coincide cu această direcție.
În continuare, putem găsi o altă direcție, perpendiculară pe prima componentă, astfel încât de-a lungul acesteia dispersia să fie maximă între toate direcțiile perpendiculare. După ce l-am găsit, obținem a doua componentă. Apoi putem continua căutarea, punând condiția că trebuie să căutăm printre direcțiile perpendiculare pe componentele deja găsite. Dacă coordonatele inițiale au fost liniar independente, atunci putem face acest lucru o dată până când dimensiunea spațiului se termină. Astfel, vom obține componente reciproc ortogonale, ordonate după ce procent din varianța datelor explică.
Desigur, componentele principale rezultate reflectă modelele interne ale datelor noastre. Dar există caracteristici mai simple care descriu și esența tiparelor existente.
Să presupunem că avem n evenimente în total. Fiecare eveniment este descris de un vector. Componentele acestui vector:
Pentru fiecare semn, puteți nota cum s-a manifestat în fiecare dintre evenimente:
Pentru oricare două caracteristici pe care se bazează descrierea, este posibil să se calculeze o valoare care arată gradul de manifestare comună a acestora. Această mărime se numește covarianță: 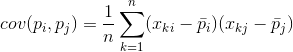
Arată cum abaterile de la valoarea medie a uneia dintre caracteristici coincid în manifestare cu abateri similare ale unei alte caracteristici. Dacă valorile medii ale caracteristicilor sunt egale cu zero, atunci covarianța ia forma: 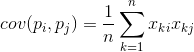
Dacă corectăm covarianța pentru abaterile standard inerente caracteristicilor, obținem un coeficient de corelație liniară, numit și coeficientul de corelație Pearson: ![]()
Coeficientul de corelare are proprietate remarcabilă. Ia valori de la -1 la 1. Mai mult, 1 înseamnă proporționalitatea directă a două mărimi, iar -1 indică relația lor liniară inversă.
Din toate covarianțele perechi ale caracteristicilor, putem crea o matrice de covarianță, care, după cum puteți vedea cu ușurință, este așteptarea matematică a produsului: ![]()
Deci, se dovedește că pentru componentele principale este adevărat:
Adică, componentele principale sau, așa cum se mai numesc și factori, sunt vectori proprii ai matricei de corelație. Ele corespund valorilor proprii. Mai mult, cu cât valoarea proprie este mai mare, cu atât procentul de varianță explicat de acest factor este mai mare.
Cunoașterea tuturor componentelor principale, pentru fiecare eveniment care este o realizare X
, putem scrie proiecțiile sale pe componentele principale:
Astfel, este posibil să se reprezinte toate evenimentele inițiale în coordonate noi, coordonatele componentelor principale: 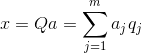
În general, se face o distincție între procedura de căutare a componentelor principale și procedura de găsire a unei baze din factori și rotația ei ulterioară, ceea ce facilitează interpretarea factorilor, dar întrucât aceste proceduri sunt apropiate din punct de vedere ideologic și dau un rezultat similar, va numi atât analiză factorială.
În spatele procedurii destul de simple de analiză factorială se află o semnificație foarte profundă. Cert este că, dacă spațiul trăsăturilor inițiale este un spațiu observabil, atunci factorii sunt trăsături care, deși descriu proprietățile lumii înconjurătoare, în cazul general (dacă nu coincid cu trăsăturile observate) sunt entități ascunse. Adică, procedura formală de analiză factorială ne permite să trecem de la fenomenele observabile la detectarea fenomenelor, deși direct invizibile, dar totuși existente în lumea înconjurătoare.
Se poate presupune că creierul nostru utilizează în mod activ selecția factorilor ca una dintre procedurile de înțelegere a lumii din jurul nostru. Prin identificarea factorilor, avem ocazia de a construi noi descrieri a ceea ce ni se întâmplă. La baza acestor noi descrieri stă exprimarea în ceea ce se întâmplă a acelor fenomene care corespund factorilor identificați.
Permiteți-mi să explic puțin esența factorilor la nivel de zi cu zi. Să presupunem că ești manager de resurse umane. Multe persoane vin la tine, iar pentru fiecare dintre ei completezi un anumit formular, unde inregistrezi diverse date observabile despre vizitator. După ce ați revizuit notele mai târziu, este posibil să descoperiți că unele grafice au o anumită relație. De exemplu, tunsorile bărbaților vor fi în medie mai scurte decât cele ale femeilor. Cel mai probabil, vei întâlni chelii doar printre bărbați, iar doar femeile vor purta ruj. Dacă analiza factorială este aplicată datelor personale, atunci genul se va dovedi a fi unul dintre factorii care explică mai multe modele simultan. Dar analiza factorială vă permite să găsiți toți factorii care explică corelațiile într-un set de date. Aceasta înseamnă că pe lângă factorul de gen, pe care îl putem observa, vor mai fi și alții, inclusiv factori impliciti, neobservabili. Și dacă genul apare explicit în chestionar, atunci altul factor important va rămâne între linii. Evaluând capacitatea oamenilor de a-și exprima gândurile, evaluând succesul în carieră, analizând notele lor de diplomă și semne similare, veți ajunge la concluzia că există o evaluare generală a inteligenței unei persoane, care nu este scrisă în mod explicit în chestionar, dar ceea ce explică multe dintre punctele sale. Evaluarea inteligenței este factorul ascuns, componenta principală cu efect explicativ ridicat. Nu observăm această componentă în mod explicit, dar înregistrăm semne care sunt corelate cu ea. Având experiență de viață, ne putem forma subconștient o idee despre inteligența interlocutorului nostru pe baza anumitor caracteristici. Procedura pe care o folosește creierul nostru în acest caz este, în esență, analiza factorială. Observând modul în care anumite fenomene apar împreună, creierul, folosind o procedură formală, identifică factorii ca o reflectare a tiparelor statistice stabile inerente lumii din jurul nostru.
Identificarea unui set de factori
Am arătat cum filtrul Hebb selectează prima componentă principală. Se pare că, cu ajutorul rețelelor neuronale, puteți obține cu ușurință nu numai prima, ci și toate celelalte componente. Acest lucru se poate face, de exemplu, în felul următor. Să presupunem că avem caracteristici de intrare. Să luăm neuronii liniari, unde .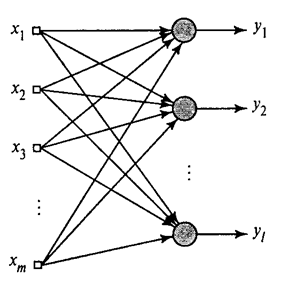
Algoritm Hebb generalizat(Khaikin, 2006)
Vom antrena primul neuron ca filtru Hebb, astfel încât să selecteze prima componentă principală. Dar vom antrena fiecare neuron ulterior pe un semnal din care vom exclude influența tuturor componentelor anterioare.
Activitate neuronală în timpul unui pas n este definit ca 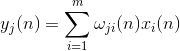
Și corectarea greutăților sinoptice este ca
unde de la 1 la , și de la 1 la .
Pentru toți neuronii, aceasta arată ca o învățare similară cu un filtru Hebb. Singura diferență este că fiecare neuron ulterior nu vede întregul semnal, ci doar ceea ce neuronii anteriori „nu au văzut”. Acest principiu se numește reevaluare. De fapt, restabilim semnalul original dintr-un set limitat de componente și forțăm următorul neuron să vadă doar restul, diferența dintre semnalul original și cel restaurat. Acest algoritm se numește algoritm Hebb generalizat.
Ceea ce nu este în întregime bun despre algoritmul Hebb generalizat este că este de natură prea „computațională”. Neuronii trebuie ordonați, iar activitatea lor trebuie numărată strict secvenţial. Acest lucru nu este foarte compatibil cu principiile de funcționare a cortexului cerebral, unde fiecare neuron, deși interacționează cu ceilalți, operează în mod autonom și unde nu există un „procesor central” clar definit care să determine succesiunea generală a evenimentelor. Din aceste motive, algoritmii numiți algoritmi de decorelație arată ceva mai atractiv.
Să ne imaginăm că avem două straturi de neuroni Z 1 și Z 2. Activitatea neuronilor din primul strat formează o anumită imagine, care este proiectată de-a lungul axonilor către stratul următor.
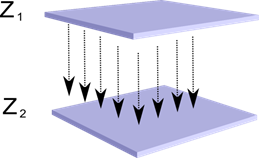
Proiecția unui strat pe altul
Acum imaginați-vă că fiecare neuron al celui de-al doilea strat are conexiuni sinaptice cu toți axonii care provin din primul strat, dacă se încadrează în limitele unei anumite vecinătăți a acestui neuron (figura de mai jos). Axonii care intră într-o astfel de zonă formează câmpul receptiv al neuronului. Câmpul receptiv al unui neuron este acel fragment de activitate generală care îi este disponibil pentru observare. Orice altceva pur și simplu nu există pentru acest neuron.
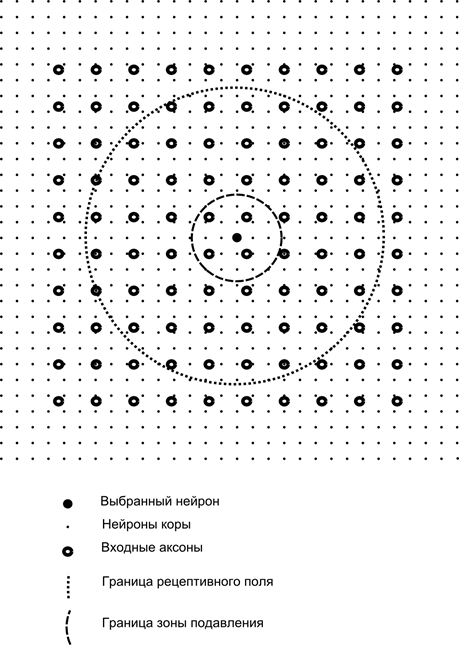
in afara de asta câmp receptiv neuron, vom introduce o zonă ceva mai mică, pe care o vom numi zonă de suprimare. Să conectăm fiecare neuron cu vecinii săi care se încadrează în această zonă. Astfel de legături se numesc laterale sau, după terminologia acceptată în biologie, laterale. Să facem conexiunile laterale inhibitoare, adică reducând activitatea neuronilor. Logica muncii lor este că un neuron activ inhibă activitatea tuturor acelor neuroni care cad în zona sa de inhibiție.
Conexiunile excitatorii și inhibitorii pot fi distribuite strict cu toți axonii sau neuronii în limitele zonelor corespunzătoare sau pot fi specificate aleatoriu, de exemplu, cu o umplere densă a unui anumit centru și o scădere exponențială a densității conexiunilor ca una. se îndepărtează de ea. Umplerea continuă este mai ușoară pentru modelare; distribuția aleatorie este mai anatomică din punct de vedere al organizării conexiunilor în cortexul real.
Funcția de activitate a neuronului poate fi scrisă:
unde este activitatea finală, este setul de axoni care se încadrează în zona receptivă a neuronului selectat, este setul de neuroni în zona de suprimare a căruia cade neuronul selectat și este puterea inhibării laterale corespunzătoare, care ia valori negative.
Această funcție de activitate este recursivă, deoarece activitatea neuronilor se dovedește a fi dependentă unul de celălalt. Acest lucru duce la faptul că calculele practice sunt efectuate iterativ.
Antrenamentul greutăților sinaptice se face în mod similar cu filtrul Hebb:
Greutățile laterale învață conform regulii anti-Hebbian, crescând inhibiția între neuronii „similari”:
Esența acestui design este că învățarea Hebbian ar trebui să conducă la alocarea pe scara neuronului a valorilor corespunzătoare primului factor principal caracteristic datelor furnizate. Dar un neuron este capabil să învețe în direcția oricărui factor numai dacă este activ. Când un neuron începe să secrete un factor și, în consecință, să răspundă la acesta, începe să blocheze activitatea neuronilor care intră în zona sa de suprimare. Dacă mai mulți neuroni concurează pentru activare, atunci competiția reciprocă duce la faptul că cel mai puternic neuron câștigă, în timp ce îi suprimă pe toți ceilalți. Alți neuroni nu au de ales decât să învețe în acele momente când nu există vecini cu ei în apropiere. activitate ridicată. Astfel, apare decorelația, adică fiecare neuron din zonă, a cărui dimensiune este determinată de mărimea zonei de suprimare, începe să-și evidențieze propriul factor, ortogonal cu toți ceilalți. Acest algoritm este numit algoritmul de extracție a componentelor principale adaptive (APEX) (Kung S., Diamantaras K.I., 1990).
Ideea inhibiției laterale este apropiată în spirit de principiul „câștigătorul ia tot”, binecunoscut din diverse modele, care permite și decorelarea zonei în care este căutat câștigătorul. Acest principiu este folosit, de exemplu, în neocognitronul de la Fukushima, hărțile auto-organizate ale lui Kohanen, iar acest principiu este folosit și în formarea binecunoscutei memorie temporală ierarhică a lui Jeff Hawkins.
Câștigătorul poate fi determinat prin simpla comparare a activității neuronilor. Dar o astfel de căutare, ușor de implementat pe un computer, este oarecum incompatibilă cu analogiile cu cortexul real. Dar dacă îți stabilești un obiectiv de a face totul la nivelul interacțiunii dintre neuroni fără a implica algoritmi externi, atunci același rezultat poate fi obținut dacă, pe lângă inhibarea laterală a vecinilor, neuronul are un efect pozitiv. părere, care îl entuziasmează. Această tehnică pentru găsirea unui câștigător este folosită, de exemplu, în rețelele de rezonanță adaptivă Grossberg.
Dacă ideologia unei rețele neuronale permite acest lucru, atunci folosirea regulii „câștigătorul ia tot” este foarte convenabilă, deoarece căutarea activității maxime este mult mai simplă decât calcularea iterativă a activităților ținând cont de inhibiția reciprocă.
Este timpul să termin această parte. S-a dovedit a fi destul de lung, dar chiar nu am vrut să împart narațiunea care era conectată în sens. Nu fi surprins de KDPV, această imagine a fost asociată pentru mine în același timp inteligenţă artificială si cu factorul principal.
Acest articol conține materiale - în mare parte în limba rusă - pentru studiu de bază rețele neuronale artificiale.
O rețea neuronală artificială, sau ANN, este un model matematic, precum și întruchiparea software sau hardware, construit pe principiul organizării și funcționării rețelelor neuronale biologice - rețele celule nervoase organism viu. Știința rețelelor neuronale există de destul de mult timp, dar tocmai în legătură cu cele mai recente realizări ale progresului științific și tehnologic această zonă începe să câștige popularitate.
Cărți
Să începem selecția cu mod clasic studiul – cu ajutorul cărților. Am selectat cărți în limba rusă din o cantitate mare exemple:
- F. Wasserman, Tehnologia neurocalculatoarelor: Teorie și practică. 1992
Cartea prezintă, într-o formă accesibilă publicului, elementele de bază ale construirii neurocomputerelor. Structura rețelelor neuronale și diverși algoritmi setările lor. Capitole separate sunt dedicate implementării rețelelor neuronale. - S. Khaikin, Rețele neuronale: curs complet. 2006
Principalele paradigme ale rețelelor neuronale artificiale sunt discutate aici. Materialul prezentat conține o justificare matematică strictă a tuturor paradigmelor rețelelor neuronale, este ilustrat cu exemple, descrieri ale experimentelor pe computer, conține multe probleme practice, precum și o bibliografie extinsă.
D. Forsythe, Computer Vision. Abordare modernă. 2004
Viziunea computerizată este una dintre cele mai solicitate zone din lume. în această etapă dezvoltarea tehnologiilor informatice digitale globale. Este necesar în producție, controlul roboților, automatizarea proceselor, aplicații medicale și militare, supraveghere prin satelit și computer calculatoare personale, în special, căutarea de imagini digitale.
Video
Nu există nimic mai accesibil și mai ușor de înțeles decât învățarea vizuală folosind video:
- Pentru a înțelege ce este învățarea automată în general, priviți aici aceste două prelegeri de la Yandex ShAD.
- Introducereîn principiile de bază ale proiectării rețelelor neuronale - excelent pentru a continua introducerea în rețelele neuronale.
- Curs de curs pe tema „Viziunea pe computer” de la Comitetul de calcul al Universității de Stat din Moscova. Viziunea computerizată este teoria și tehnologia creării de sisteme artificiale care detectează și clasifică obiecte în imagini și videoclipuri. Aceste prelegeri pot fi considerate o introducere în această știință interesantă și complexă.
Resurse educaționale și link-uri utile
- Portal de inteligență artificială.
- Laboratorul „Eu sunt inteligența”.
- Rețele neuronale în Matlab.
- Rețele neuronale în Python (engleză):
- Clasificarea textului folosind ;
- Simplu .
- Rețeaua neuronală activată.
O serie de publicații noastre pe această temă
Am publicat anterior un curs #neuralnetwork@tproger pe rețelele neuronale. În această listă, publicațiile sunt aranjate în ordinea studiului pentru confortul dvs.
Manualul fundamental proaspăt tradus de S. Khaikin (a fost tradusă a doua ediție americană din 1999) se pretinde cu adevărat a fi evenimentul anului 2006 în literatura rusă despre neuroinformatică. Dar trebuie remarcat faptul că, deși traducerea a fost efectuată fără greșeli evidente, notele de subsol și comentariile traducătorilor nu ar strica să clarifice terminologia (deoarece același lucru poate fi numit în neuroinformatică, statistică și identificarea sistemului prin cuvinte diferite, este necesar fie pentru a reduce termenii la o zonă, fie pentru a oferi liste de sinonime - nu toți cititorii vor avea o perspectivă largă). Comentariile ar putea reflecta, de asemenea, progresul în domeniul rețelelor neuronale artificiale care a avut loc de la publicarea originalului în limba engleză. Sper că cartea va fi la cerere și că se vor face modificări atunci când ediția va fi retipărită. Mai mult, există un număr semnificativ de greșeli de scriere în formulele matematice. Această pagină este dedicată în principal corectării greșelilor de scriere. Dar trebuie remarcat faptul că nu garantez caracterul complet al listei de inexactități prezentate aici - am citit cartea „în diagonală”, în potriviri. grade diferite atenție, așa că s-ar putea să fi omis ceva (sau să fi făcut eu o greșeală).
Capitolul 1
- P.32 al doilea paragraf. Numai aici cuvântul „performanță” poate fi înțeles ca viteza de funcționare, puterea computerului. Mai târziu în carte, „performanță” va însemna acuratețea, calitatea activității rețelei neuronale (de exemplu, la p. 73 în al doilea paragraf din partea de jos).
- p.35 p.7. „Implementabilitatea VLSI” este mai bine tradusă nu ca „scalabilitate”, ci ca „implementabilitate efectivă pe VLSI - circuite integrate la scară foarte mare”.
- p.39 p.7. Cuvântul „spike” - „emisie, impuls” în neuroștiința în limba rusă este destul de des și de obicei transliterat simplu ca „pic”.
- P.49 titlul paragrafului. Poate că un termen mai bun ar fi „graf direcționat” în loc de „graf direcționat”.
- P.76 al treilea paragraf. În loc de un link, probabil ar trebui să existe un link către cartea lui Ashby.
- P.99 concluzia 1. De asemenea, este necesar să se adauge și cazul satisfacerii simultane a acestor condiții și cu semnul „
- P.105 paragraful 2. Trebuie să introduceți cuvântul „vizibil” înainte de (vizibil).
capitolul 2
- P.94 nota de subsol 2. Referirea la este cel mai probabil incorectă, deoarece Nu este o carte și titlul nu prea i se potrivește.
- P.122 ultimul paragraf. Am râs de expresia „deformarea structurii neuronilor”: până când evenimentul extern al unei comoții cerebrale nu este satisfăcut, o persoană nu își va aminti acest eveniment. Cel mai probabil, s-a susținut că memoria se realizează numai prin deconectarea intrărilor sinaptice (terminale) de la tentaculele dendritelor sau trecerea de la un tentacul la altul (termeni din Fig. 1.2 la p. 40, deoarece această figură este potrivită pentru ilustrare) . Acestea. Creierul nostru este viu și în mișcare.
- P.129 formula (2.39). În loc de X acolo trebuie sa fie X.
- P.129 formule (2.40), (2.41), (2.44). Superscriptul ar trebui să fie qîn loc de m.
- P.137 primul paragraf și formula (2.61). E ar trebui să fie în cursiv. Și în formulele (2.64), (2.65), (2.67), (2.68) de la p. 138.
- P.142 formula (142). Adăugați 0 după prima săgeată.
- P.142 ultimul paragraf. Inainte de ultimul cuvant introduceți „minus”.
- P.147 primul paragraf. | L|=l. Acestea. variabil lîn partea dreaptă a expresiei ar trebui să fie dat cu caractere cursive (deoarece versiunea din carte o confundă cu una).
- P.151 formula (2,90). Introduceți în linia de sus după bretele F.
- formula C.151 (2,91). Introduceți „la” înainte N.
- C.160 ultimul paragraf din nota de subsol. „pentru cantități mici” ar trebui înlocuit cu „pentru cantități mari”.
capitolul 3
- P.173 Fig.3.1. Variabilele trebuie date cu caractere cursive în conformitate cu notația folosită în carte, deoarece aceste variabile sunt scalare.
- P.176 formule (3.5), (3.7). Trebuie să fie w* în loc de w* .
- C.176 ultima linie. Cel mai probabil trebuie să vă referiți, deși această problemă poate fi luată în considerare și în cea specificată.
- P.179 nota de subsol. Ar trebui să fie „derivată a lui f(w) în raport cu w”
- P.180 ultimul rând înainte de nota de subsol. Poate fi mai bine să luați în schimb, dar linkul poate fi incorect.
- P.184 expresie intermediară în linia superioară a formulei (3.30). În loc de X(n) ar trebui să fie X(i)
- P.200 paragraful după formula (3.59). A râs de „inegalitatea Gucci-Schwartz”. Ar trebui să existe inegalitatea Cauchy-Schwarz, care este cunoscută de toată lumea de la cursul universitar.
- P.204 primul paragraf al secțiunii 3.10 este despre transformarea unui clasificator bayesian într-un separator liniar într-un mediu gaussian. Aceasta se referă la condiția ca matricele de covarianță ale ambelor clase să fie identice (va fi introdusă în secțiunea de la p. 207), dar când aud expresia „mediu gaussian” îmi amintesc de obicei situația generalizată a două distribuții normale cu covarianță arbitrară. matrice, când Bayes nu poate degenera într-un separator liniar, dar oferă o suprafață de împărțire pătratică.
- P.206 formula (3.77). În continuare, în loc de λ indicat în formulă, Λ va fi tipărit de mai multe ori în text și în Fig. 3.10.
- P.216 sarcina 3.11. Ceea ce este dat în limita superioară a sumei trebuie mutat sub semnul sumei (iar minusul poate fi plasat în fața sumei). Tot în paragraful de după această formulă, în loc de w T X acolo trebuie sa fie w T X
capitolul 4
Comentariul meu despre capitol: un coșmar, un începător în rețelele neuronale și metodele de optimizare, chiar și după citirea capitolului de mai multe ori și încercări repetate (fie intenționat, fie la întâmplare), este puțin probabil să programeze corect antrenamentul unei rețele neuronale folosind backpropagation. metodă. Cel puțin, când iau în considerare doar studenții din universitățile tehnice provinciale, sunt dispus să argumentez despre asta cu mize destul de mari. Prezentarea a amestecat atât lucrurile necesare, cât și cele inutile într-o grămadă, fără a pune accent și a complica prea mult prezentarea (asumând o abordare „totul sau nimic” în loc de adăugarea pas cu pas a procedurilor). Plus o mulțime de empiric. De ce să nu schițați pur și simplu metodologia de calcul al gradientului unei funcții complexe (o rețea neuronală plus o funcție obiectivă asupra ieșirii sale și, dacă este necesar, asupra proprietăților rețelei neuronale), apoi, ca în capitolul 6, trimiteți cititorii la gradient metode de optimizare fără restricții (în capitolul 6 referirea se referă la metodele de programare pătratică) și conturează câteva exemple istorice de abordări corecte și incorecte pentru utilizarea gradienților calculați în rețea din punctul de vedere al teoriei optimizării gradientului și maximizării ratei de convergență (rata de invatare).
Ce lucruri suplimentare ați dori să vedeți în capitol (sau carte). În primul rând, alte funcții obiective decât cele mai mici pătrate, în special pentru antrenarea unei rețele de clasificatori (de exemplu, funcția de entropie încrucișată). În al doilea rând, o evidențiere mai clară a posibilității de a avea o funcție obiectiv formată din mai mulți termeni: folosirea exemplului de regularizare conform lui Tihonov prin minimizarea explicită, pe lângă valoarea erorii în sine, și a gradientului scalar pătrat al semnalelor de ieșire a rețelei prin greutățile sinapselor (lucrare în comun a lui LeCun și Drucker 1991-92), fie folosind exemplul metodei de căutare Flat minina a lui Hochreiter și Schmidhuber, fie exemplul metodei CLearning de curățare a semnalelor de intrare în rețea de Andreas Weigend și colab. În al treilea rând, o descriere mai detaliată a posibilității de calculare a derivatelor secundare în rețea (lucrări indicate de LeCun și Drucker, metode enumerate în recenzie). În al patrulea rând, o descriere mai detaliată a metodelor de calcul al conținutului și al utilității informațiilor elemente diferiteși semnale în rețea (adică, determinarea conținutului de informații al intrărilor, posibilitatea de a reduce nu numai sinapsele folosind metodele descrise în carte, ci și reducerea neuronilor întregi și există, de asemenea, o grămadă de alte metode pentru reducerea sinapselor). În al cincilea rând, există o indicație explicită (cititorii nu își vor da seama singuri) despre capacitatea de a calcula gradientul folosind semnalele de intrare ale rețelei (pentru rezolvarea problemelor inverse pe rețelele neuronale antrenate să rezolve problema directă, pentru prezentarea metoda de învățare). În plus, pentru acesta și alte capitole în care se pune problema învățării supravegheate, descrieți mai detaliat ideea curbelor de învățare pentru rețelele neuronale.
capitolul 5
- P.357 după formula (5.23). Mai departe pe mai multe pagini E poate fi dat cu caractere cursive sau aldine, iar schimbarea formei de scriere este destul de întâmplătoare. Mai corect - cu caractere cursive, pt E(F), E s(F), E c (F), E(F,h).
- P.361 formula (5.31). În loc de indice H acolo trebuie sa fie H .
- P.363 ultimul paragraf. „...prin o combinație liniară...” în loc de „...prin o suprapunere liniară...”.
- P.364 formula (5.43). Eliminați 1/λ.
- P.367 formula (5.59). σ în loc de δ.
- P.369 după formula (5.65). Din nou, ar trebui să existe „combinație liniară” în loc de „suprapunere liniară”.
- P.373 a treia linie a formulei (5.74). Introduceți o paranteză de deschidere înainte de a doua t i .
- P.382 formula (5.112). La limita inferioară a sumei, adăugați „nu este egal cu k".
- P.390 titlul secțiunii 5.12. În știința în limba rusă, în loc de „regresie nucleu”, sunt de obicei folosiți termenii „regresie neparametrică” (așa se numește această metodă de statistică în rusă) sau „regresie nucleu” (dacă este tradus „direct”).
- P.393 formula (5.135). Introduceți „...pentru toți...” ca în (5.139) pe pagina următoare.
- P.399 paragraf „de mijloc”. „...algoritm de grupare prin k-in medie...”, atunci cuvântul „medie” nu va mai fi omis.
- P.403 listă nenumerotată. Autorii trag concluzii prea globale și lipsite de ambiguitate dintr-un experiment, deși sunt în mare măsură de acord.
- P.404 este primul articol din listă. Nu înțeleg, mai ales în ceea ce privește „influența asupra parametrilor de intrare”. Mai degrabă decât mai multă valoareλ, cu atât mai puțină influență a datelor în general asupra proprietăților finale ale modelului.
- P.408 primul paragraf. Link-ul către este discutabil, poate că va funcționa.
- P.408 rândul 6 al paragrafului 2. „funcție de bază” în loc de „funcție fundamentală”.
Capitolul 6
- P.431 ultima teză înainte de secțiunea 6.4. Nu am înțeles „mai bine” alegerii propuse prin media eșantionului (și se pare că aceasta ar da b 0 nu va fi posibil).
- P.434 formula (6.35). Index i ultimul X nu ar trebui să existe.
- P.435 formule nenumărate în teorema lui Mercer. În loc de ψ ar trebui să existe φ.
- P.444 nota de subsol. Numele de familie Huber a fost tradus anterior în rusă ca Huber, nu Haber (de exemplu, traducerea cărții sale în timpul URSS: Huber, „Robustețea în statistică”).
Capitolul 7 (nu complet)
- P.459 a treia linie de sus. Definiția termenului „algoritm slab de învățare” este dată la p. 467 în al doilea paragraf de sus.
- P.459 subparagrafe nenumerotate din paragraful 2. Termenul „rețea gateway” ca traducere a termenului „rețea gateway” este prea neîndemânatic, dar nu există încă o altă opțiune (și bună) în rusă. Probabil ar fi mai bine să folosim termenul de „rețea de ponderare”, care este universal atât pentru cazul comutării hard (multiplicatori de 0 sau 1 pentru semnalul controlat), cât și pentru controlul soft al coeficientului de atenuare (multiplicatori din gamă).
- str.463 str.2. Înlăturăm particula „nu” din această propoziție - dispersia ansamblului este mai mică decât dispersia funcțiilor individuale.
- P.471 primele linii. „Performanța” (vă reamintim că „performanța” este înțeleasă aici nu în sensul vitezei, ci în sensul acurateței soluției și generalizării - vezi comentariul nostru de la p. 32) a metodei de amplificare inițiale, de asemenea, depinde asupra repartizărilor formate în timpul funcționării sale pentru experții secundi și ulteriori.
- P.472 tabelul 7.2 ultimul rând. Trebuie să fie F aripioare ( X)=…
Bibliografie
- De multe ori cuvintele aplicare, aproximare, abordare, aplicat, suport, cartografiere, aplicabilitate, superior sunt scrise cu una p.
- . Scrierea corectă Numele unuia dintre autori pot fi văzute în.
- . Prenume corect Muller - ca și omonimul lui.
- . Primul autor - B u ntine.
- . Lansat în același NIPS ca și .
- . Ultimul dintre autori este corect numit în.
- . Avem nevoie de slabi in loc de saptamana.
- . Ultimul autor este corect numit în .
- . Prima - Landa u.
- . Acesta este un capitol dintr-o carte.
- . Sch ö lkopf.
- . În titlu - „... bia s termen". Se scrie corect în duplicat.
- . În titlu - „…gamm pe".
- . Repeta.



